Motivation
Der Smart Growing Cells Algorithmus ist ein Ansatz zur Oberflächenrekonstruktion aus Punktwolken mittels eines künstlichen neuronalen Netzes. Er wird zum Beispiel eingesetzt um Messdaten, wie sie z.B. von einem Laserscanner erzeugt werden, in ein für die Computergrafik typisches Netz aus Dreiecken zu überführen.
Das Verfahren wurde von Hendrik Annuth im Rahmen seiner Dissertation implementiert und verfeinert. In meinem 5. Semester habe ich, zusammen mit einem Kommilitonen, den Versuch unternommen die damals bestehende Implementierung zu parallelisieren.
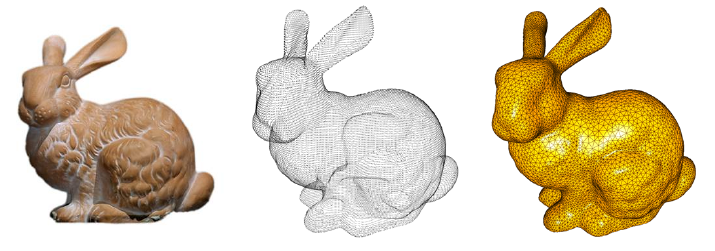
Ablauf einer Rekonstruktion
Das Verfahren beginnt mit einem relativ einfachen Grundobjekt, im konkreten Fall typischerweise einer einfachen Pyramide. Im Laufe der Rekonstruktion gibt es dann drei Basisoperationen, die für jeden Punkt des Dreieckgeflechts eine von drei Operationen ausführt. Die genaue Art der Operation hängt dabei von den umgebenden Punkten ab, welche als Eingabe für den Algorithmus fungieren.
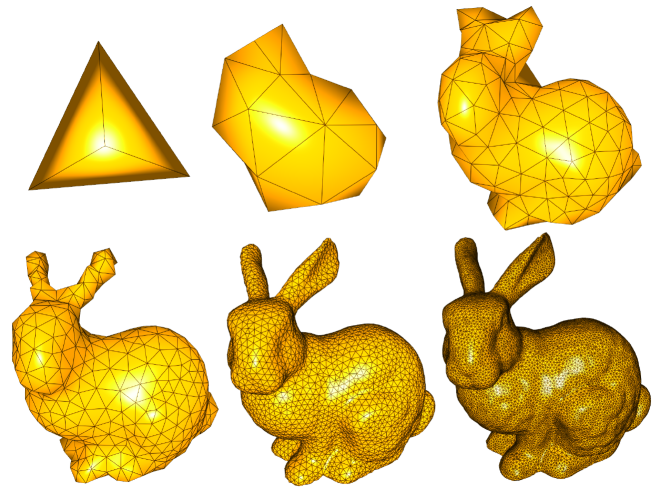
Bei diesen Grundoperationen handelt es sich um Glätten, Aufteilen und Verschmelzen. Anschaulich kann man sich vorstellen, dass versucht wird die bestehenden Punkte des Meshs möglichst nahe an die Punktwolke anzupassen. Ist das gegenwärtige Mesh nicht fein genug, es besteht also aus zu wenig Dreiecken, wird an geeigneter Stelle ein neues Dreieck hinzugefügt. Ist das aktuelle Mesh zu fein, werden einzelne Dreiecke entfernt.
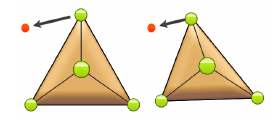
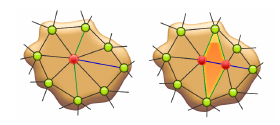
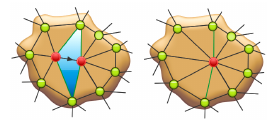
Eignung des Verfahrens für die Parallelisierung
Das Verfahren ist relativ gleichgültig bezüglich der exakten Reihenfolge, in der die Grundoperationen durchgeführt werden. Außerdem hat jede dieser Operationen nur relativ lokale Auswirkungen, ein Großteil des Meshes bleibt von den Änderungen also unberührt. Wir haben für die Parallelisierung also die Theorie aufgestellt, dass wird diesen "Standardprozess" der drei Grundoperationen einfach räumlich getrennt mehrfach auf dem gleichen Mesh ausführen können. Außerdem sollte die Anzahl der möglichen Threads irgendwie von der Größe des Meshes abhängen.
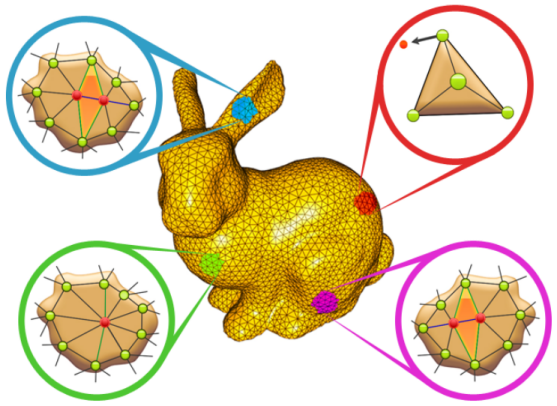
Eignung der Implementierung für die Parallelisierung
Die von uns vorgefundene Implementierung war hochgradig optimiert, speziell was die Speicherverwaltung angeht. Der Speicher umgeht die in C++ übliche Speicherverwaltung mit new und delete zugunsten eines eigens implementierten Speicherpools. Diese Implementierung steigert die Cache Lokalität und verringert den Overhead bei häufigen kleineren Allokationen. Da die Klassen für den Pool sowohl als Speichermanager als auch als eigene Datenstruktur genutzt wurden war es schwierig zu bestimmen, wann und unter welchen Umständen auf welche Speicherbereiche lesend oder schreibend zugegriffen wird.
Wir haben uns daher als Lösungsansatz für einen Octree entschieden, bei dem die Unterbäume von einzelnen Threads gesperrt werden können. Der Octree garantiert einen gewissen räumlichen Zusammenhang, allerdings keine sehr granulare Unterscheidung. Es könnten z.B. auch voneinander unabhängige Teilmeshes Teil des gleichen Octrees sein. Bei sehr kleinen Meshes ist zudem schlichtweg nicht genug Raum vorhanden, hier lohnt sich keine Parallelisierung.
Die Implementierung
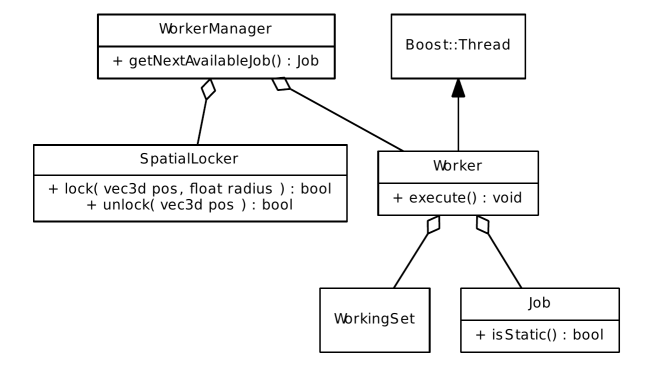
Die konkrete softwaretechnische Umsetzung folgt dem Master-Worker Muster. Es existiert also ein "Hauptthread" in Form des WorkerManager der die konkreten Aufgaben bestimmt und diese an einzelne Worker verteilt. Es werden also Job Instanzen auf Vorrat erzeugt und auf einen Stack gelegt.

Der WorkerManager erzeugt die Aufgaben allerdings unabhängig von den Sperrbereichen, da er nicht vorhersehen kann wann welcher Bereich nicht zur Verfügung steht. Für jede Pop Operation muss also geprüft werden ob die betroffenen Bereiche gerade frei sind, das ist in unserer Implementierung die Aufgabe des SpatialLocker.
Die Ergebnisse
Wir hatten leider wenig Zeit die Implementierung noch zu optimieren, weil wir mehr Zeit als ursprünglich erhofft mit der Besprechung von Detailfragen bezüglich der Umsetzung. Im Endeffekt haben wir einen Verbesserung der Geschwindigkeit von etwa 10% je zusätzlichem Kern erreicht. Bei den relativ langen Laufzeiten die der Algorithmus zur Durchführung benötigt, typischerweise im Bereich von einigen Stunden für reale Modelle, ist das dennoch eine relevante Verbesserung.
Als Hauptproblem konnten wir den großen Anteil von verworfenen Jobs ausmachen, zeitweise wurden weniger als 10% der angelegten Jobs auch tatsächlich durchgeführt. Um diesen Ansatz weiter zu verfolgen bräuchte es also eine geeignetere Implementierung des SpatialLocker, der die lock und unlock Operationen granularer durchführen kann.